一、高校大数据及其处理架构
高校中汇聚着大量的信息,从学生角度来看,包括联系方式等基本信息,食堂消费、住宿晚归等生活信息,选课、课后作业、借阅图书、成绩等学习信息,参与的社团、竞赛、讲座等第二课堂信息;
从教师角度来看,包含教学任务、课件等教学信息,论文著作、科学研究数据等科研信息;
从管理者的角度来看,包含学校的资产信息、师资信息、招生就业信息等。
同时随着移动互联网以及物联网等新技术的兴起,学校师生主动产生和由设备自动收集的信息越来越多,如微博、微信等社交信息,各类搜索点击记录信息等。
上述信息存在着数据量大、结构复杂、产生频率快的特点。
这导致利用常用软件工具捕获、管理和处理此类数据所耗费时间超过了可容忍的时间。
大数据的处理流程与一般数据的处理过程类似,可以定义为在合适工具的辅助下对广泛异构的数据源进行抽取和集成,将结果按照一定的标准统一存储,利用合适的数据分析技术对存储的数据进行分析从中提取有益的知识,并利用恰当的方式将结果展现给终端用户。
具体来说可以分为数据抽取与集成、数据分析和数据展示。
1、数据抽取与集成
大数据的数据来源非常广泛,既包括传统的关系型数据库,也包括XML 等半结构化数据,以及以视频、音频、文本和其他形式存在的非结构化数据。
数据抽取和集成要解决的主要问题就是收集各种碎片化的数据,对数据进行清洗,保证数据质量,同时根据时间演进不断更新数据模式,确定数据实体及其之间的关系,最终将数据按照统一的格式进行存储,以便提供给上层用来进行数据分析。
目前高校已经基本建立了完备的管理信息系统、学习管理系统等,在统一数据中心中积累了大量的结构化数据;同时各类系统中还散布着大量的半结构化和非结构化数据。半结构化和非结构化的数据经过一定处理后,可以转化为更容易分析使用的结构化数据。
2、数据分析
经过抽取和集成得到的数据, 需要经过分析挖掘其潜在的价值。传统的数据挖掘、机器学习、统计分析等方法仍然可以用来对数据进行分析,只是需要根据大数据的特征进行调整。
首先,为了实现对海量数据的分析,需要依Map/Reduce 模型,将数据拆分处理,然后再将结果汇总,一个完整的分析可能会经过多层类似的处理过程;
其次,大数据的应用通常具有实时性的特点,数据的价值会随着时间的流逝而递减,因此分析方法需要平衡处理的效率和准确率;
最后,大数据一般构建在云计算平台之上,分析方法需要考虑与云计算平台的集成或做为一种云服务。
3、数据展示
数据分析得到的分析结果,需要以直观可理解的方式呈献给最终用户,在大数据时代,数据分析产生的结果有可能也是非常大量的,且结果之间的关联关系复杂、数据维度更多,数据可视化技术通过更加适合人类思维的图形化的方式展示数据分析结果,已经被证明是展示数据分析结果非常有效的方法。常见的可视化方法有:多维叠加式数据可视化、数据在空间、时间坐标中的变化和对比等,当然要将枯燥的信息转换为美丽的、令人印象深刻的图形,需要较高的技术素养和艺术素养。
很多高校正在使用大数据分析技术解决遇到的实际问题,如美国德克萨斯大学利用大数据技术分析学校用户IT 使用行为产生的数据,确定用户行为异常,审计IT 基础环境,制定安全防护措施。
其他的一些应用场景包括分析学生参与网络课堂产生的数据,进而确定如何改进课程讲述方式,达到因材施教的教育目标。
高校可以在就业情况分析、学习行为分析、学科规划、心理咨询、校友联络等方面借助大数据分析技术,挖掘数据中潜在的价值。
4、就业情况分析
当前市场经济高速发展、高校不断扩招、就业制度改革不断深化和毕业生数量逐年增加、社会整体就业形势日益严峻,大学生就业问题己经越来越成为目前大家共同关心的话题,研究大学生就业问题具有紧迫性和重要性。
本文提出在大数据分析框架下的就业问题分析思路。
1)、数据来源
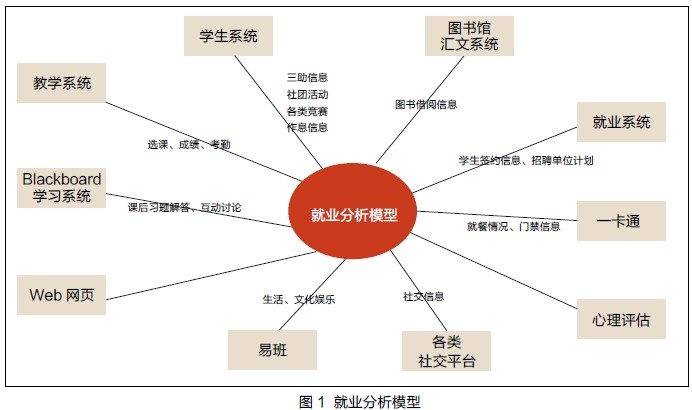
传统的就业分析一般从就业单位、就业地区、所在院系专业、性别、签约类别、就业年份等维度来分析,得到的只是一般意义上的统计结果,对于指导单个学生的就业以及预测未来的就业情况发挥的作用比较有限。应用大数据分析技术,就可以将学生就业模型涉及到的学习情况、社团信息、生活信息、校外实习、参加的竞赛及获奖情况、所投公司当年的招聘计划、历届学生在所投公司的表现等众多的信息进行收集。以上海财经大学为例,可以从图1 所示的各类系统中抽取学生的各类信息,构成就业分析模型所需的各类数据。
2)、 数据抽取与存储
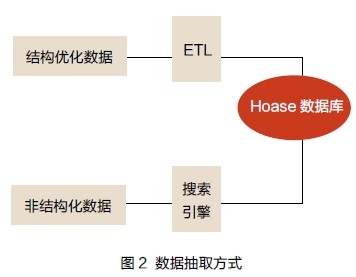
针对数据来源的不同,我们采取不同的数据抽取方式,对于结构良好的各信息系统的数据,我们采用ETL 工具如InformaticaPowercenter、Kettle 将数据抽取到HBase 数据库中;对于Web 网页这类非结构化数据,通过Nutch 进行抓取,Solr 对数据进行索引后存储到Hbase 数据库中,示意图如图2 所示。
Hbase 数据库是一个开源的高可靠性、高性能、可伸缩、并非建立在关系模型基础上的分布式数据库,用以存储大规模结构化数据。
3)、 数据分析
将就业分析模型所需的数据存储在Hbase 数据库后,可以利用Hive 对Hbase中的数据进行查询和分析。
Hive 提供了一种简单的类SQL 查询语言,十分适合数据仓库的统计分析。
通过Hive 我们可以实现传统数据仓库所实现的对就业数据的汇总统计分析,而且可以容易的扩展其存储能力和计算能力。
除了数据统计分析之外,我们还可以利用Mahout 这个机器学习工具对数据进行监督学习和无监督学习。
监督学习使用先验知识对数据进行分类;
无监督学习则由计算机自己学习处理数据,并在做出判断后给予一定的激励或惩罚。在进行就业分析时,我们可以使用Mahout 已经实现的具体方法。首先是协作筛选,通过分析已就业学生的成绩、参加的社团活动、关注的行业、性格特点、就业单位、就业岗位等,计算学生之间的相似度,为即将毕业的学生推荐适合的就业单位和岗位,提供个性化的服务;
其次是聚类,这是一种无监督的机器学习方法,我们可以通过不同的维度将未能及时就业的学生进行分析,从中找出其共同的特点,再通过比较在校学生的相关属性,及时对学生给出预警,以便其在后续的学习和生活中加以改进,如图3 所示。

4. 数据展示
在数据展示层, 我们可以使用Tableau 软件将分析的结果进行可视化的展示,Tableau 将数据与美观的图表完美地结合在一起,它包含非常多的预定义的图表格式,同时还可以将时间、地图等多种维度在单一的图表中进行展示。
学习行为分析
为了支持学生的自主学习,高校一般都有自己的学习管理系统如Blackboard、Sakai 等。这些学习管理系统为学生、教师提供了课程学习和交流的空间。美国教育部教育技术办公室认为教育数据分为键击层(keystroke level)、回答层(answer level)、学期层(session level)、学生层(student level)、教室层(classroom level)、教师层(teacher level)和学校层(school level),数据就寓居在这些不同的层之中。
一般高校每年的开课数在数千门,学生数在数万人,产生的数据量非常大。
应用大数据分析技术使得监控学生的每一个学习行为变为了可能,学生在回答一个问题时用了多长时间,哪些问题被跳过了,为了回答问题而作的研究工作等都可以获得,用这些学生学习的行为档案创造适应性的学习系统能够提高学生的学习效果。
学科规划
促进学科交叉融合发展,构筑有生命力的学科生态,打造凸显核心竞争力的高水平学科是学校学科规划的重要任务。
借助大数据分析技术,充分收集各学科的教学状态数据、科研项目数据、前沿发展动态等信息,从而分析学科建设存在的不足,确定学科未来发展的方向,发掘出潜在的具有国际视野的学科带头人。
心理咨询
论坛、微博等平台上每天都会产生由评论、帖子、留言等数据,这些数据集反映了师生的思想情况、情感走向和行为动态,对这些数据进行科学的存储、管理并使用大数据技术进行有效的分析利用,建立师生思想情感模型,对掌握师生心理健康程度,有针对性地加强对师生的心理辅导有着重要的意义。
校友联络
校友资源犹如一座座宝藏,对高校的发展建设有着不可替代的重要作用,是高校工作的重要组成部分。有效地把校友联络起来、团结起来,对学校的建设和发展具有重要意义。利用传统的管理方法,仅校友信息收集就要耗费大量的时间和精力。
利用大数据技术,收集各类社交网站上的非结构化数据,通过分类、聚类等数据挖掘方法,确定校友身份并收集其联系方式、参加的活动信息等,可以大大提高校友数据收集的效率,为以后利用校友资源提供良好的基础。
二、应用难点与对策
大数据在高校应用的美好前景令人神往,但目前大数据的应用还存在很多应用难点,主要有数据集成困难、数据分析方法有待改进和数据隐私问题。
1、数据集成
在很多高校中,因为管理信息系统设计时未考虑到对一些过程数据的收集,导致在分析时缺乏必要的数据来源,需要对应用系统进行扩展;同时对于定义良好的结构化数据很多高校也尚未很好的集成。
在大数据时代,异构的数据类型、广泛存在的数据来源、参差不齐的数据质量给数据集成带来了新的挑战。高校应该探索融合结构化、半结构化、非结构化数据的统一模型,同时提高数据采集的质量,强化数据文化。
2、数据分析方法
半结构化和非结构化数据的迅猛增长,给传统的聚类、关联分析等数据挖掘技术带来了巨大的冲击和挑战。
一方面,很多应用场景要求数据的实时分析;
另一方面缺乏对半结构化和非结构化数据的先验知识,难以构建其间的关联关系。
高校需要紧密跟踪业界对大数据分析方法的研究动态,同时通过高校间的协作沟通探索新型的数据分析方法。
3、数据隐私
大数据分析的数据基础必然建立在获取更多个人信息之上,而且通过分析还可以使数据之间产生关联关系,进而揭示更多的个人隐私。然而为了保护隐私就将所有数据加以隐藏,那么数据的价值就无法体现。
这种矛盾在相当长的时间内必将一直存在,需要通过技术和制度的完善逐步解决。
移动互联、MOOC 等技术的不断兴起给高校的发展带来了极大的挑战,为了应对这种挑战,高校应当充分发挥大数据在其中的支撑作用。在人才培养、科学研究和管理等方面广泛收集过程数据,结合可视化技术充分分析和挖掘蕴含在数据之中的丰富价值。
同时我们需要在高校内倡导和强化数据文化,建立持久运作的收集、分析数据并将分析结果转换为教育决策和实践的体系,真正发挥大数据在高校发展中的价值。
